Conjunct
A formal grammar for Malayalam conjunct
In Malayalam a conjunct(കൂട്ടക്ഷരം) is formed by combining 2 or more consonants by Virama(ചന്ദ്രക്കല). “ക്ക” is a conjunct with 2 consonants, formed by ക + ് + ക. സ്ത്ര is a conjuct with 3 consonants സ+ ് + ത +്+ ര. ന്ത്ര്യ is a conjunct with 4 consonants – ന + ് + ത + ് + ര + ് + യ. Conjuncts with more than 4 consonant is rare. ഗ്ദ്ധ്ര്യ is formed by 5 consonants.
Can we define this formation in a formal grammar?
Let us try. For the simplicity, I am using Parser Expression Grammar formalism since we can quickly write a parser for that to test and evaluate.
Before that let us define the conjuct in plain English in a bit more concise and unambigous way.
Conjunct: A Consonant combined with another Conjunct or Consonant using Virama
We need to define Consonant and Virama also.
Virama: ്.
Consonants – Any of the set [കഖഗഘങചഛജഝഞടഠഡഢണതഥദധനപഫബഭമയരലവശഷസഹളഴറ]
Writing this in PEG syntax
You can try this in a PEG evaluator and try various conjucts to see if they all getting parsed. Use https://pegjs.org/online, copy paste the above grammar try inputs like ന്ത്ര്യ.
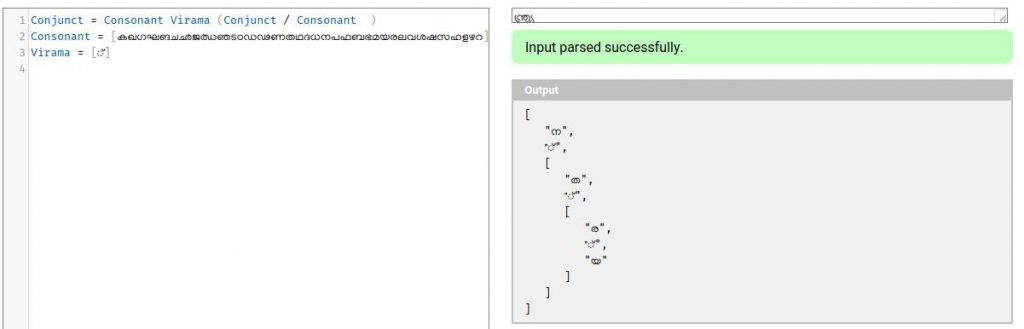
Let us look at the definition again.
This is a tail recursion. Meaning, The **Conjuct ** get expanded towards the end of the expression. Can we rewrite this using a Left recursion? We can. see:
This will have the same result of our previous expression. We can also rewrite our plain English definition as well accordingly:
Conjunct: A Conjunct or Consonant combined with another Consonant using Virama
There is a problem with this new definition since it is Left recursion, depending up on the parser implementation, it can cause infinite recursion. The PEGjs parser which we used above for testing and evaluation does not support Left recursion since it is a top down parser(recursive descent parser). You can try modify the above pegjs grammar in the online evaluation tool, you will see the parser warns about ininite recursion.
But if the parser is capable of avoiding this issue, nothing stops you to write the grammar using Left recursion. LALR parsers such as GNU Bison can very well support left recursion. But big issue here is GNU Flex/Bison used for writing such grammars does not support Unicode!. You can make it working by doing some low level byte manipulation. I did not try.
One more thing: I wrote ( Conjunct / Consonant ) instead of (Consonant / Conjunct ). The order was chosen intentionally since the matches are done left to right. Since a Conjunct anyway start with a Consonant, the parsing will proceed with that path. We avoid it by using the Conjunct, Consonant order.
Last updated